

こんにちは!みやしんです。
これまで普通にyoloを使って物体検出する方法やVoTTを使ったアノテーション方法をご紹介してきました。
今回はyoloをファインチューニング、つまり再学習させて物体検出をしていきたいと思います。
これまでの記事を参考にしたい方はこちらをご覧ください。

まずは上記の記事を読んでyoloが動く環境を整えてからこの先へ進んで頂いた方が良いかもです。初心者でも分かるように丁寧に書きましたのでおススメです。
それでははじめていきましょう!!
あと、皆さんも毎日めっちゃ忙しいと思いますが、何とか時間を作って自己投資は続けると良いですよ👍僕も以前は、仕事をしながらプログラミングスクールに通ったこともありますし、今も自己投資はずっと続けるようにしています!
物体検出をもっと学びたい方

keras-yolo v3のファインチューニングの流れ
1、https://github.com/sleepless-se/keras-yolo3 をクローンしてkeras-yolo v3をダウンロード 2、画像(教師データ、テストデータ用)を準備して加工 3、VoTTを使ってアノテーション 4、アノテーションファイルをyolo用に変換 5、yoloのファインチューニング開始
こんな感じです。1つ1つ順番にやっていけば大丈夫です。
https://github.com/sleepless-se/keras-yolo3 をクローンしてkeras-yolo v3をダウンロード
yoloの学習をしやすいように、誰かがアレンジしてくれているみたいです。
とても使いやすいので使っていきましょう!
こんな感じです!
画像(教師データ、テストデータ用)を準備して加工
次に物体検出したい画像を集めます。
この記事では例として信号機を物体検出したいと思います。
yoloでは320px × 320pixに画像の大きさを調整する必要があります。
画像の加工方法(拡大、縮小、切り抜き等)は、下記の記事を参考にしていただくと良いと思います。
作った画像は「keras-yolo3-sample」フォルダー内の「resize_image」フォルダーへ保存しておいてください。

VoTTを使ってアノテーション
続いてresize_imageフォルダー内に保存した画像の信号機部分にアノテーションをします。
アノテーションとは、信号機はここにありますよ~と四角で囲ってあげることを言います。
今回はアノテーションツールのVoTTというアプリを使っていきます。アノテーションファイルはPascal VOCというフォーマットで書き出します。
詳しい使い方はこちらの記事にまとめましたので参考にしてみてください。

アノテーションしたファイルをYOLOv3形式に合わせる
上記の記事を参考にしてアノテーションして頂くとPascal VOCでアノテーションファイルを書き出せます。するとresize_imageフォルダー内にxxx-PascalVOC-exportという名前のフォルダーが出来ていたと思います。

これらのフォルダやファイルをkeras-yolo3/VOCDevkit/VOC2007に移動させます。

続いて、train.txt、test.txt、val.txtの3つのファイルを作成します。
下記のコマンドを実行すると、3つのファイルが作成されます。
cdでカレントディレクトリをkeras-yolo3-sampleにして実行します。
python make_train_files.py
すると、こんな感じで処理が進みます。

この処理は、書き出された学習用のアノテーションファイルをtrain.txtとval.txtにまとめてval.txtの中身をシャッフルして3割ほどtest.txtに移動させて保存するそうです。(誰かが作ってくださった便利なスクリプトです)
作成されたファイルはkeras-yolo3-sample/VOCDevkit/VOC2007/ImageSets/Main から確認できます。
・ラベル名_train.txt
・ラベル名_val.txt
というファイルがVoTTによって作成されたファイルです。

今回はアノテーションのタグ付けはtrafficlightだけでしたので、_train _valは1つずつのみ作成されます。複数タグ付けを設定したときはその数だけファイルが作成されます。
スクリプトを実行して3つのファイルが作成されます。
- train.txt
- test.txt
- val.txt

YOLOの学習用に変換
VOTTでアノテーションしたファイルはそのままではYOLOの学習に使えないのでYOLOの学習用に変換します。
keras-yolo-sampleフォルダーの直下にあるvoc_annotation.pyを実行して変換します。
voc_annotation.pyの6行目付近のclassesのリストを自分で学習させる内容に合わせて修正します。
今回はタグ付けが1種類だけなので、
classes = ["trafficlight"]


とします。そしてスクリプトを実行します。
python voc_annotation.py

これでYOLO学習用に変換されます。
変換されたファイルはkeras-yolo3-sampleフォルダー内のmodel_dataに保存されます。

YOLOでファインチューニング 学習開始
YOLOv3のweights(重み)をダウンロードしてきて学習用に変換します。
元々のYOLOの重みがkeras用ではないため変換します。
まずは以下のリンクでweightsをダウンロードできます。


ダウンロードさいたファイル(yolov3.weights)はkeras-yolo-sampleフォルダーに入れます。
ファイル名も適宜修正しましょう。(例 yolo3 (3).weights → yolo3.weights)


続いて、重みファイルを下記のコマンドで変換します。
python convert.py -w yolov3.cfg yolov3.weights model_data/yolo_weights.h5

変換終了するとこんな感じです。
いよいよ学習を開始します。
下記のコマンドを実行すると学習が始まります。
python train.py

1分ほど待つと学習が開始されます。CPUしかついていない通常のPCで行いましたが、batch_sizeが8以下でないとメモリーがオーバーフローしてしまい学習できませんでした。他に開いていたファイルも全て閉じて実行しました。
バッチサイズを変えたい方は59行目付近のbatch_sizeがデフォルトは32になっていますので修正しましょう。


教示データが500枚弱で大体1.5日くらいかかったと思います。
マシンスペックも重要ですね。
学習済みモデルを実行
学習済みのモデルは keras-yolo-sample/logs/000に保存されている.h5ファイルを使います。
学習中にベストスコアが出たタイミングでも.h5ファイルで保存するようになっています。
今回はtrained_weights_stage_1.h5が時間的に一番最新のモデルでしたのでこれをメインで使いました。色々なモデルを試してみると検出力が変わっていくのが分かるので面白いです。
実際に学習済みのモデルを使って物体検出をやってみましょう!
keras-yolo-sampleフォルダーの直下にyolo.pyがあります。これを開くと24行目付近にどの学習モデルを使うか設定できるようになっています。
"model_path": 'logs/000/ファイル名.h5'


いよいよ最後です。
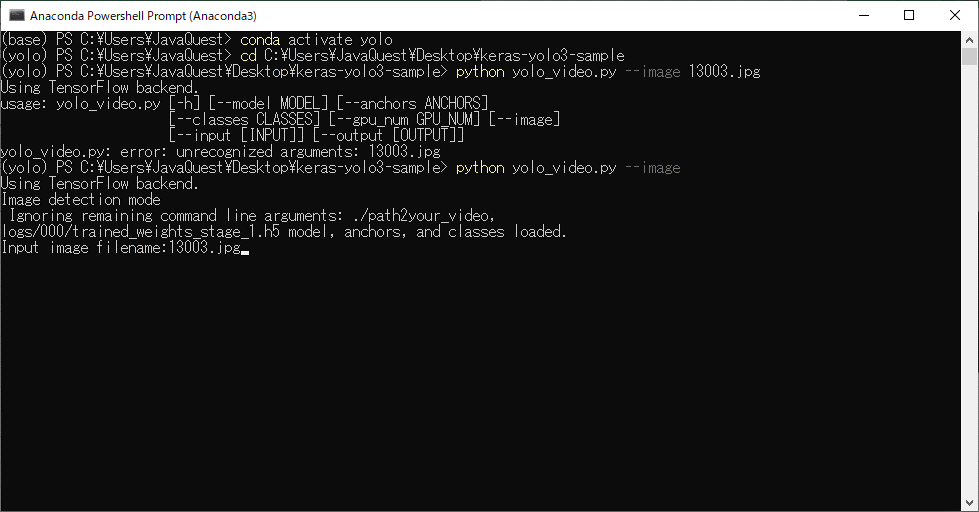
画像で物体検出する場合は、下記のコマンドを入力。
python yolo_video.py --image
すると後に画像のファイル名をコマンドプロント上で聞かれますので入力して完了です。
動画の場合は、
python yolo_video.py --input ファイル名.mp4
でOKです。
この辺は下記の記事も参考にしてみてください。
物体検出としては以上になります。画像認識など基礎的なところから始めたい人、コードにもっと触れて理解した人は下記の本がオススメです。僕も買って持っていますがコードもしっかり書いてあり一つ一つ丁寧で理解しやすいです。
Python、AI、機械学習について、初心者の方、プログラミングスクールに興味のある方、E資格を取得したい方、更に実践的なスキルを磨きたい方は下記の記事もご参考ください。

以上になります。最後まで読んでくださりありがとうございました!
参考にしたサイト
今回の記事はこちらのサイトを参考にしました。



コメント