
みなさん、こんにちは!みやしんです。
今回は、PyCaretについてご紹介します。
PyCaretとは、データの前処理自動化、モデルの比較自動化、チューニングの自動化などを行ってくれる、とても便利なライブラリです。

PyCaretは、scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Rayなどのいくつかの機械学習ライブラリとフレームワークをまとめたPythonラッパーです。
Classification(分類)、Regression(回帰)、Clustering(クラスタリング)、Anomaly Detection(異常検出)、Natural Language Processing(自然言語処理)、Time Series Forecasting(時系列予測)のような処理をたった数行で実装できてしまうので、過去に機械学習の経験がある方は、その簡単さに驚愕だと思います。
世間にも様々なAutoML(AML)ツールがあると思いますが、かなり高額なものが多いと思います。
PyCaretはPythonのライブラリの1つなので、とくに費用は掛かりません。すばらしいですね!
それでは、早速やっていきましょう!
なんか、わくわくするにゃ!
PythonやAIをもっと勉強したい方🤗

実行環境
今回は、Google Colaboratory を使って進めていきます。
PyCaretをインストール
pipでインストールします。
!pip install pycaret参考にPyCaretのHPも載せておきます。
★PyCaret
データセットのダウンロード
データセットをダウンロードします。
今回はPyCaretで用意されているデータの’diamond’を使います。ダイアモンドの価格を予想します。
今回は分類を行いますので「regression」から全てインポートします。
from pycaret.regression import *
from pycaret.datasets import get_dataget_dataの引数にデータを指定します。
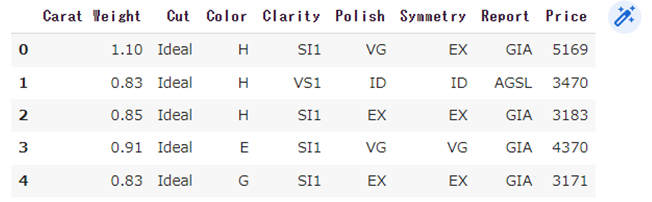
dataset = get_data('diamond')‘diamond’のデータを見てみると下記のようになります。
なお、ダウンロードできるデータの一覧はこちらです。
★データセット
データの前処理
第1引数:使うデータセット、第2引数:目的変数 を指定します。
たった1行です。
exp = setup(dataset, target='Price')実行すると、
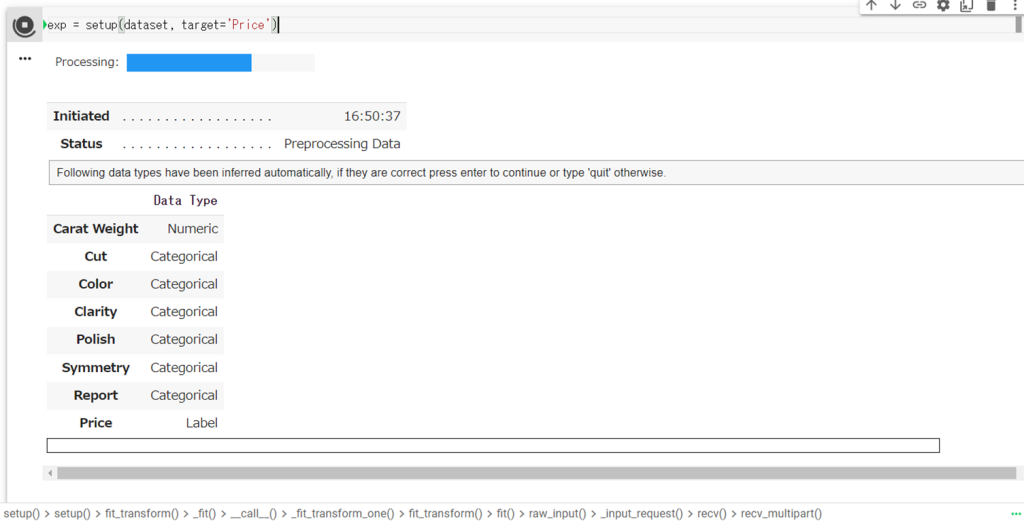
各説明変数のデータタイプが表示されますので、問題なければ「Enter」を押しましょう。
ここでEnterを押さない先に進まないので気を付けてにゃ!
実行結果はこんな感じです。色々な設定や指標が表示されています。
参考程度に見てみると面白いですよ。

モデルの比較
モデルの比較も1行でできます。
compare_models()ridge回帰やlasso回帰など様々なアルゴリズムで計算しています。
R2(決定係数)が高い順に並んでいます。一番良いのは「et : Extra Trees Regressor」になります。
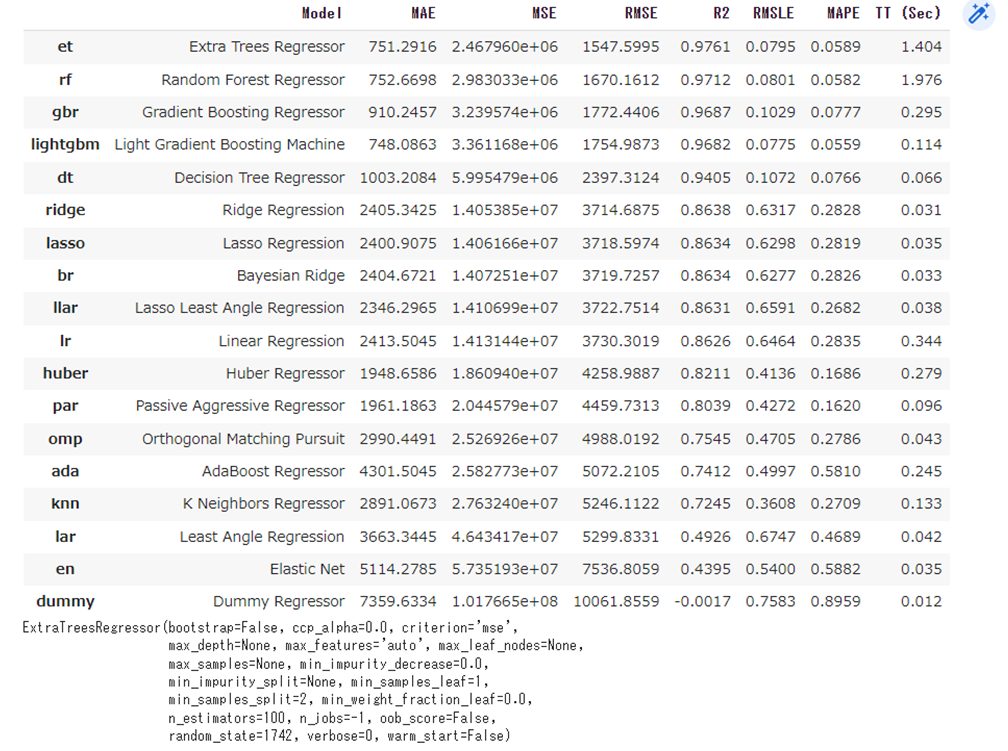
一番下段に、Extra Trees Regressorの設定されているパラメータが載っています。
モデルの作成
一番良さそうなExtra Trees Regressorを使ってモデルを作成します。
これも1行です。
model = create_model('et')10分割のクロスバリデーションを実施します。
結果がこちらです。
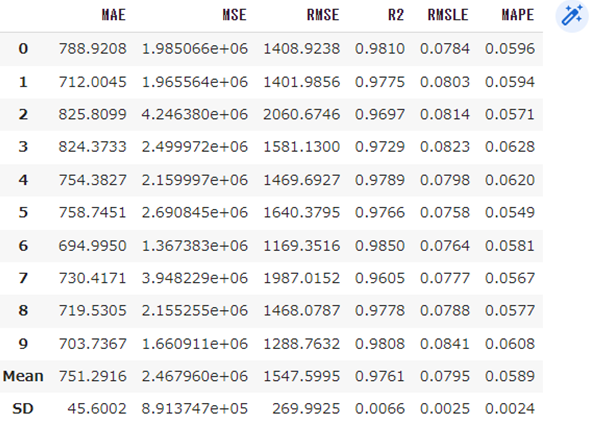
print(model)モデルのハイパーパラメータを表示します。

ハイパーパラメータのチューニング
tune_modelの引数に作成したモデルを入れます。
これも1行です。
tuned_model = tune_model(model)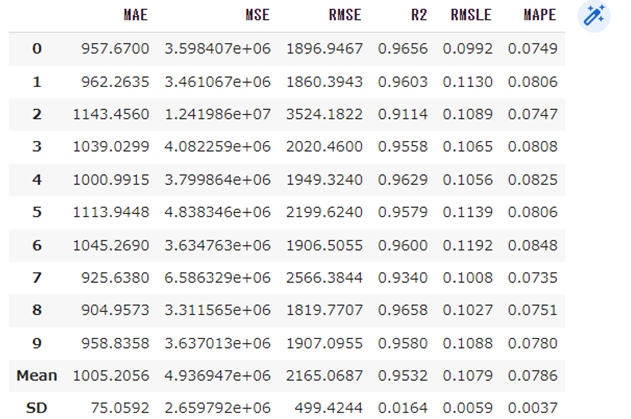
チューニングに少し時間が掛かるので待ちましょう!
予測
テストデータに対して予測します。
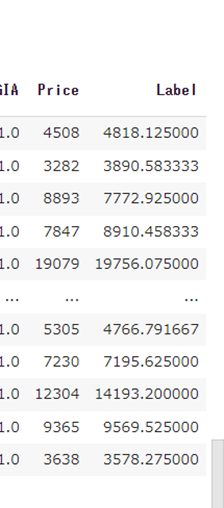
predict_model(tuned_model)
上記の表の一番右にある、「Price」と「Laber」を比較しましょう。概ね合っているように見えます。
下に拡大したものを載せます。
結果をプロットする
これも1行でプロットできます。
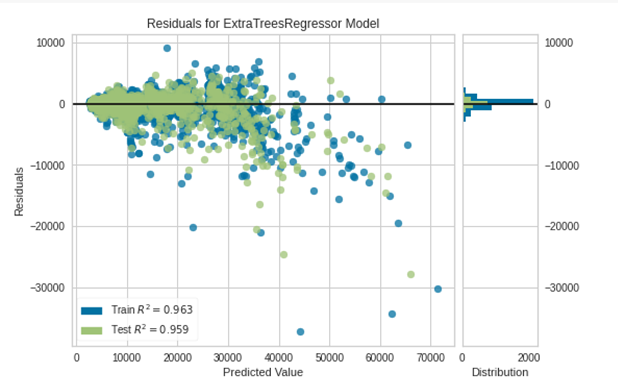
plot_model(tuned_model)残差の分布を表示します。
以下のように書くと、特徴量毎の重要度を確認します。引数に’feature’を入れます。
plot_model(tuned_model, plot='feature')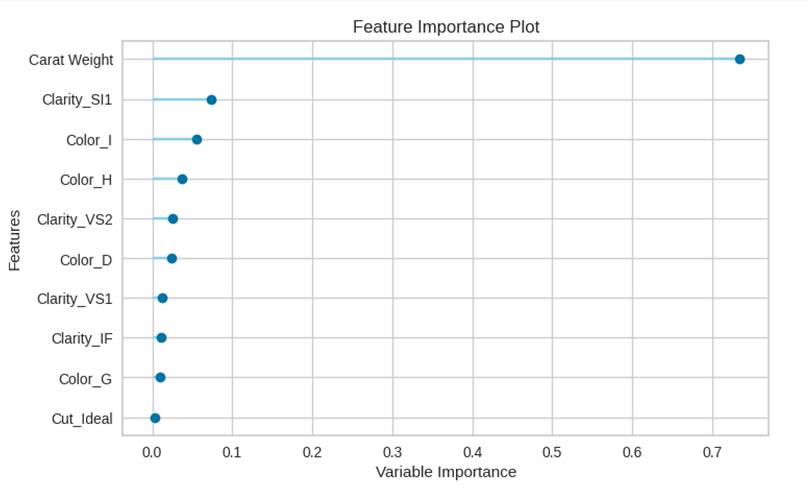
重さが一番効いていることが分かりますね!
上記はダイアモンドの価格を予想する「回帰」でした。
以下にワイン品質を分ける「分類」についても簡単に解説します。
回帰も分類も殆ど同じです。
分類 (classfication) ワイン品質
!pip install pycaret今回は分類ですので、classification にします。(回帰はregression)
from pycaret.classification import *
from pycaret.datasets import get_dataデータは’wine’をダウンロードします。
dataset = get_data('wine')
品質’quality’を目的変数にします。
exp = setup(dataset, target='quality')
compare_models()et : Extra Trees Classifier のAccuracyが0.6659で一番高いですね
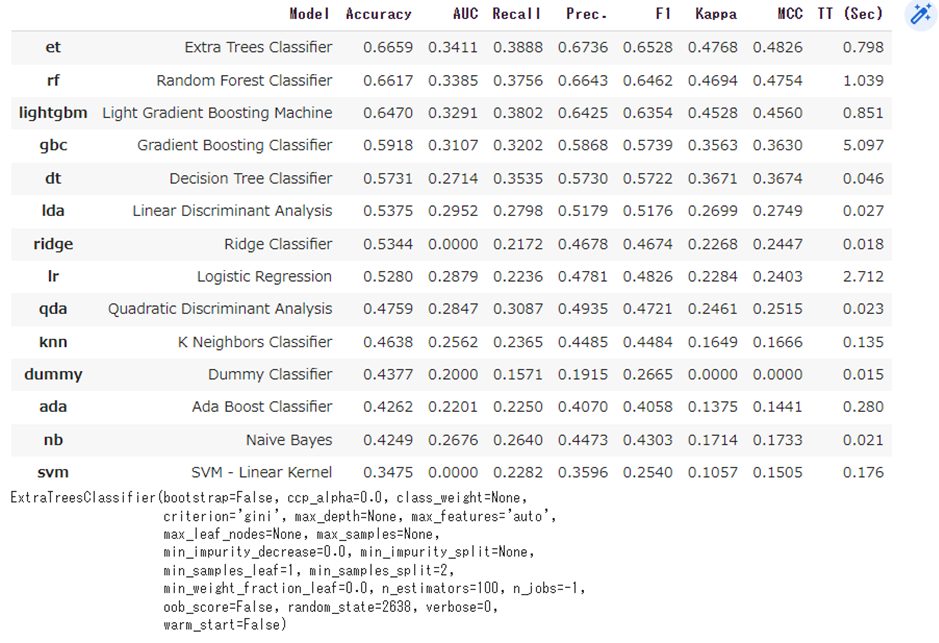
model = create_model('et')et : Extra Trees Classifier でモデルを作成します。
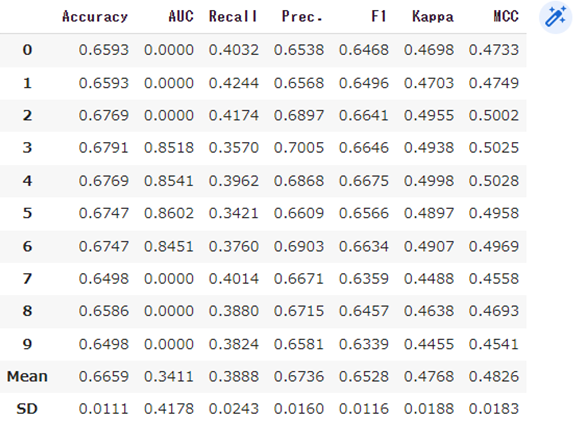
print(model)
tuned_model = tune_model(model)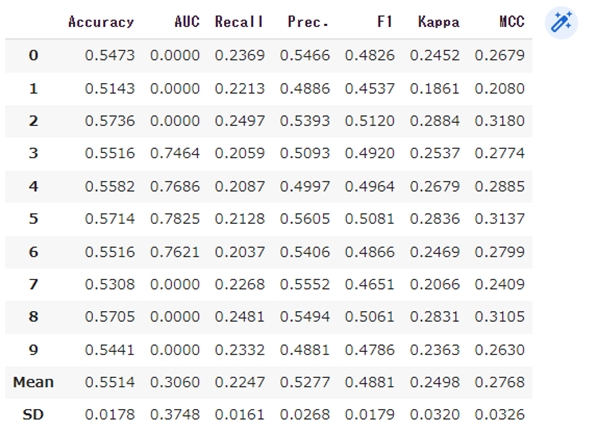
チューニングしたらAccuracyが下がってしまいました。
こういったこともあるんですね。一応、先に進めます。
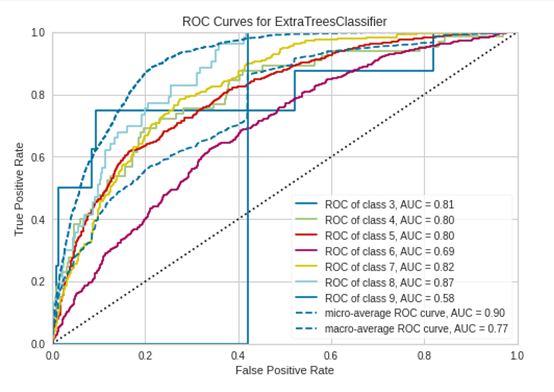
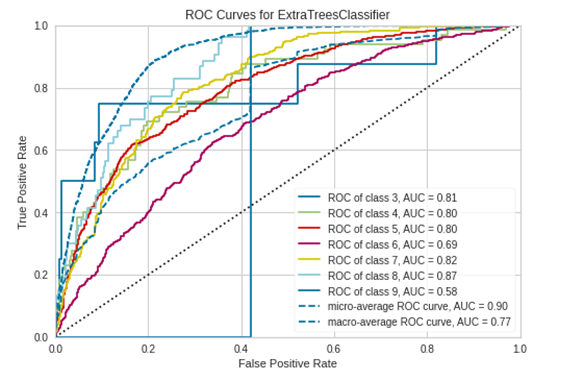
plot_model(tuned_model)ROC曲線とAUC曲線が出ました。
plot_model(tuned_model, plot='feature')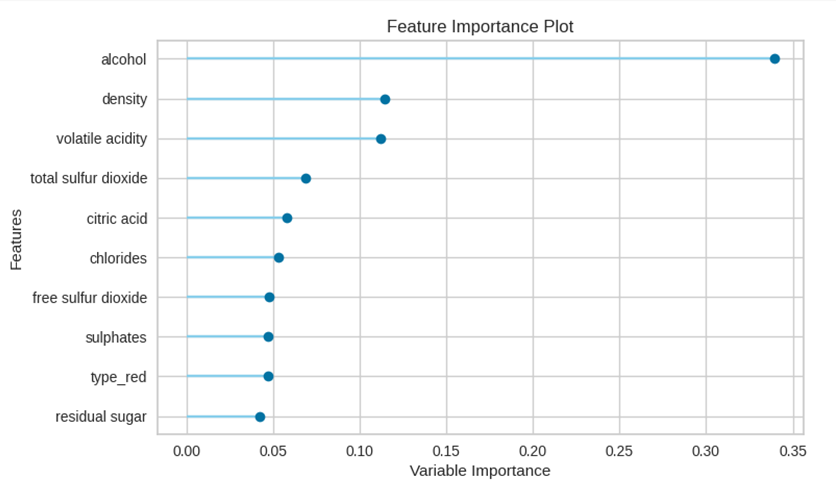
アルコールが効いてるんですね!
AUC曲線を表示します。
plot_model(tuned_model, plot='auc')plot_model(tuned_model)で表示したものと同じですね!
混同行列をプロットします
plot_model(tuned_model, plot='confusion_matrix')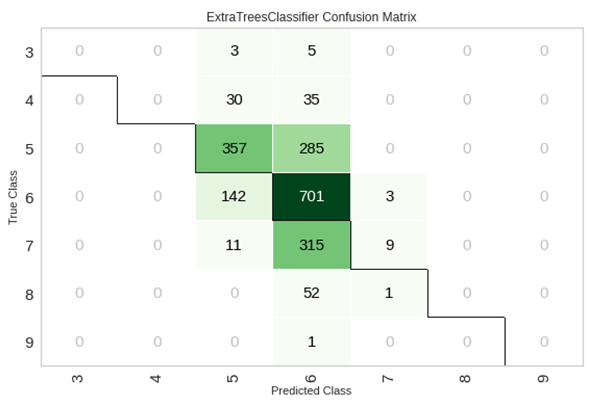
evaluate_model() で複数の評価を同時に行うことができます。
evaluate_model(tuned_model)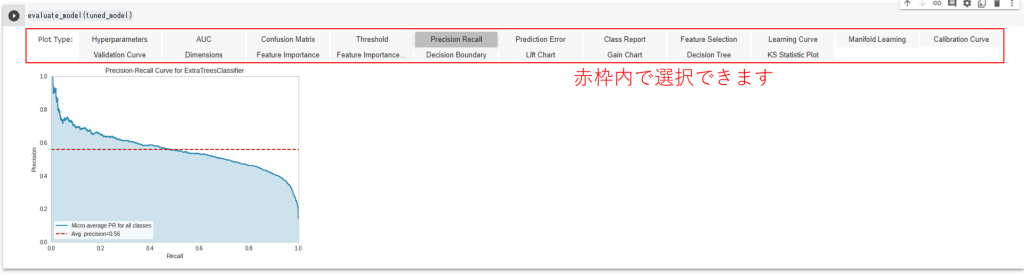
PythonやAIをもっと勉強したい方🤗


コメント
Pycaretがインストールできなくて困っています。
Could not install packages due to an OSError: [Errno 2]
No such file or directory: ‘/Users/~/opt/anaconda3/lib/python3.7/site-packages/matplotlib-3.4.3.dist-info/METADATA’
と表示されますが、どうしたらいいですか?
ご連絡ありがとうございます。Anacondaのupdate「conda update conda」、Pycaret用に仮想環境構築「conda create -n [name] python=[version] [library]」されてみてどうでしょうか?既にお済でしょうか?
少し訂正します。conda create -n [name] python=[version] でした。
「conda」では「conda install -c conda-forge pycaret」
または、pipをアップグレードします。
pip install –upgrade pip
もしくは、
python -m pip install –upgrade pip
してから
!pip install pycaret
はどうでしょうか?
いつも楽しく勉強させてもらってます。
tune_modelで出てきた、表のAUC値(10個分)と、plot_modelで出てきたAUC値が大きく違うと思うのですが、どうしてでしょうか?
なかなか考えても難しく。。。
教えていただけますでしょうか?
ご連絡くださりありがとうございます!
ホントですね。なんでだろう。
何か処理が違うのかな?また分かりましたらご連絡いたします。