

色々なことができるOpenCVですが、今回は骨格検出AIを使ってみたいと思います。
OpenCVって他にも物体検出ができたり、顔検出が出来たりホント便利!
管理人のみやしんが本を出版しました🤗✨Pythonをやってみたいけれど、作りたいものや目標はとくにない、そんな方でも挫折しないで楽しく安心して学習を進められる、とっても素敵な本です🤗


この記事で出来る事 (骨格検出、骨格推定、姿勢推定)
骨格検出、骨格推定、姿勢推定、色々な言い方をしますが、基本的には同じ意味を指します。
人物画像からその人の姿勢(骨格)をAIが推定してくれます。
実際にやってみると、こんな感じです。


この技術を応用すると、色々なスポーツのフォーム改善、猫背のような姿勢改善、製造現場での作業改善など色々なシーンで活躍できる技術になります。OpenCVとフリーで落とせる学習済みモデルをメインで使っています。OpenCVって便利ですね!
では、早速やってみましょう!🤗
OpenCVを使った過去の記事もご参考にどうぞ🌟
■物体検出(Mask-RCNN)

■特徴量マッチング

■写真内の物体までの距離推定

■顔検出してモザイクを掛ける

環境構築、実装方法
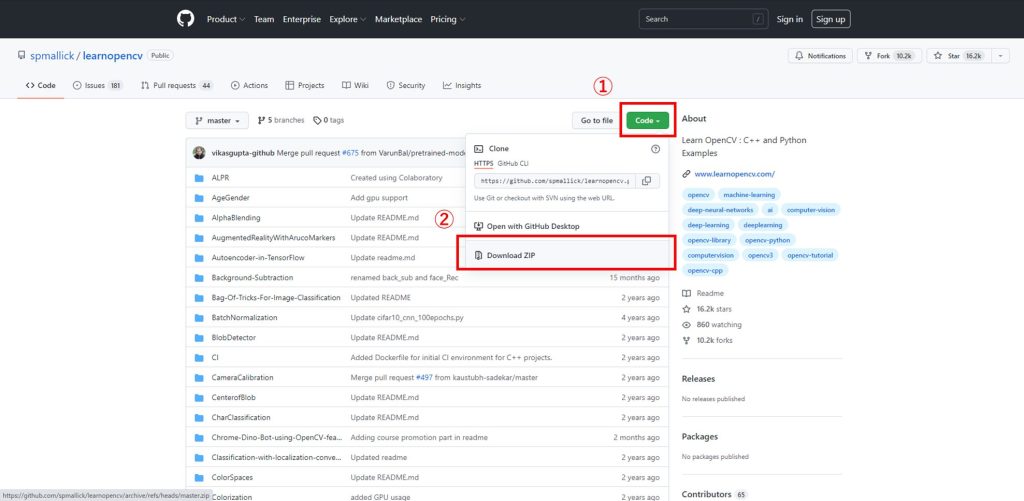
learnopencvをダウンロード
まずは「learnopencv」をダウンロードします。
このlearnopencvの中には物体検出などOpenCVで活用できる便利なツールがたくさん入っているので他のも試してみると面白いと思います!
learnopencvはこちらからダウンロードしてください。
以下の①②の順でダウンロードできます。
OpenPose
learnopencvをダウンロードしましたら「OpenPose」というフォルダを探しましょう。
学習済みモデルをダウンロード
OpenPoseフォルダの中に「getModels.sh」というファイルが入っていますので、それを開いてみましょう。すると下記のように記載されています。
# ------------------------- POSE MODELS -------------------------
# Downloading the pose-model trained on COCO
COCO_POSE_URL="https://www.dropbox.com/s/2h2bv29a130sgrk/pose_iter_440000.caffemodel"
COCO_FOLDER="pose/coco/"
wget -c ${COCO_POSE_URL} -P ${COCO_FOLDER}
# Downloading the pose-model trained on MPI
MPI_POSE_URL="https://www.dropbox.com/s/drumc6dzllfed16/pose_iter_160000.caffemodel"
MPI_FOLDER="pose/mpi/"
wget -c ${MPI_POSE_URL} -P ${MPI_FOLDER}上記の2つのURLにアクセスして学習済みモデルをダウンロードしましょう。
・pose_iter_440000.caffemodel
・pose_iter_160000.caffemodel
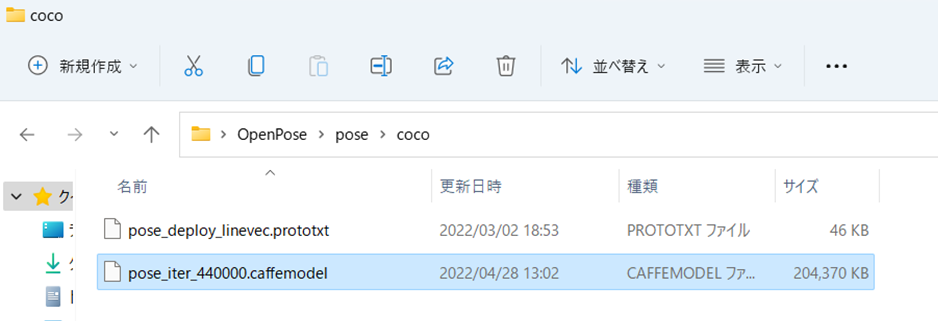
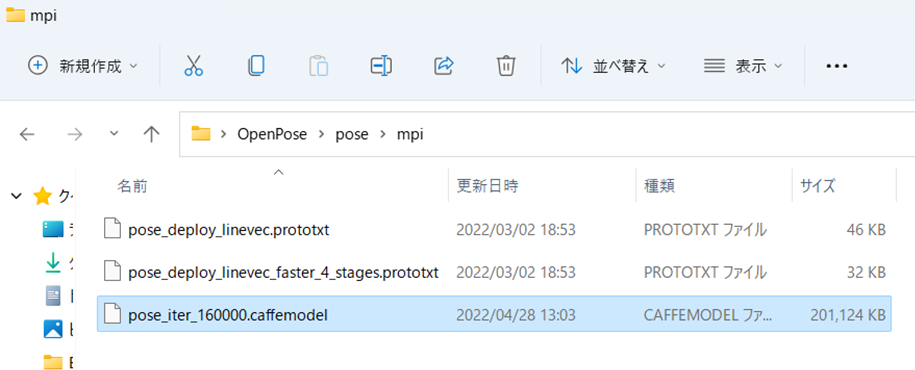
ダウンロードしましたら、モデルを決められた位置に配置します。下記のフォルダ構成で配置してください。

こんな感じですね!
pose_iter_440000.caffemodel
pose_iter_160000.caffemodel
ライブラリのインストール
ライブラリをインストールして環境構築しましょう
opencv
pip install opencv-pythonnumpy
pip install numpymatplotlib
pip install matplotlibこれでOKです!
Jupyter Notebookで実行
OpenPoseフォルダの中に「OpenPose_Notebook.ipynb」というJupyter Notebook用のファイルがありますので、これを使います。
まずは必要なライブラリをインポートします
import cv2
import time
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline続いて、使用するモデルを指定します
COCOとMPIは学習済みモデルです。 COCOは18ポイント、MPIは15ポイントを出力します。
最初のMODE=”MPI”のところを”COCO”に変えるとモデルを変えられます。
MODE = "MPI"
if MODE is "COCO":
protoFile = "pose/coco/pose_deploy_linevec.prototxt"
weightsFile = "pose/coco/pose_iter_440000.caffemodel"
nPoints = 18
POSE_PAIRS = [ [1,0],[1,2],[1,5],[2,3],[3,4],[5,6],[6,7],[1,8],[8,9],[9,10],[1,11],[11,12],[12,13],[0,14],[0,15],[14,16],[15,17]]
elif MODE is "MPI" :
protoFile = "pose/mpi/pose_deploy_linevec_faster_4_stages.prototxt"
weightsFile = "pose/mpi/pose_iter_160000.caffemodel"
nPoints = 15
POSE_PAIRS = [[0,1], [1,2], [2,3], [3,4], [1,5], [5,6], [6,7], [1,14], [14,8], [8,9], [9,10], [14,11], [11,12], [12,13] ]
複数の人がいる画像を読み込んで、モデルが何を見ているかを確認します
image1 = cv2.imread("multiple.jpeg")
frameWidth = image1.shape[1]
frameHeight = image1.shape[0]
threshold = 0.1ディープニューラルネットワーク(DNN)に画像を渡します
net = cv2.dnn.readNetFromCaffe(protoFile, weightsFile)
inWidth = 368
inHeight = 368
inpBlob = cv2.dnn.blobFromImage(image1, 1.0 / 255, (inWidth, inHeight),
(0, 0, 0), swapRB=False, crop=False)
net.setInput(inpBlob)
output = net.forward()
H = output.shape[2]
W = output.shape[3]
print(output.shape)特定のキーポイントの出力から確率マップをスライスし、画像にヒートマップをプロットします(サイズ変更後)
i = 5
probMap = output[0, i, :, :]
probMap = cv2.resize(probMap, (image1.shape[1], image1.shape[0]))
plt.figure(figsize=[14,10])
plt.imshow(cv2.cvtColor(image1, cv2.COLOR_BGR2RGB))
plt.imshow(probMap, alpha=0.6)
plt.colorbar()
plt.axis("off")モデルが肩の部分に着目して見ていることが分かりました。

同様に、i=5→24に変えて画像にプロットします
i = 24
probMap = output[0, i, :, :]
probMap = cv2.resize(probMap, (image1.shape[1], image1.shape[0]))
plt.figure(figsize=[14,10])
plt.imshow(cv2.cvtColor(image1, cv2.COLOR_BGR2RGB))
plt.imshow(probMap, alpha=0.6)
plt.colorbar()
plt.axis("off")少し見ているポイントがズレました。顎から肩くらいのところをモデルがみています。

次に、一人だけの画像のキーポイントを確認します。
画像”single.jpeg”を使います。他の画像を使いたいときは下記の1行目の”single.jpeg”を用意した画像のファイル名に変えてください。
frame = cv2.imread("single.jpeg")
frameCopy = np.copy(frame)
frameWidth = frame.shape[1]
frameHeight = frame.shape[0]
threshold = 0.1ディープニューラルネットワークに画像を渡します
inpBlob = cv2.dnn.blobFromImage(frame, 1.0 / 255, (inWidth, inHeight),
(0, 0, 0), swapRB=False, crop=False)
net.setInput(inpBlob)
output = net.forward()
H = output.shape[2]
W = output.shape[3]キーポイントをプロットして骨格図を作成します
# Empty list to store the detected keypoints
points = []
for i in range(nPoints):
# confidence map of corresponding body's part.
probMap = output[0, i, :, :]
# Find global maxima of the probMap.
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
# Scale the point to fit on the original image
x = (frameWidth * point[0]) / W
y = (frameHeight * point[1]) / H
if prob > threshold :
cv2.circle(frameCopy, (int(x), int(y)), 8, (0, 255, 255), thickness=-1, lineType=cv2.FILLED)
cv2.putText(frameCopy, "{}".format(i), (int(x), int(y)), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, lineType=cv2.LINE_AA)
cv2.circle(frame, (int(x), int(y)), 8, (0, 0, 255), thickness=-1, lineType=cv2.FILLED)
# Add the point to the list if the probability is greater than the threshold
points.append((int(x), int(y)))
else :
points.append(None)
# Draw Skeleton
for pair in POSE_PAIRS:
partA = pair[0]
partB = pair[1]
if points[partA] and points[partB]:
cv2.line(frame, points[partA], points[partB], (0, 255, 255), 3)
plt.figure(figsize=[10,10])
plt.imshow(cv2.cvtColor(frameCopy, cv2.COLOR_BGR2RGB))
plt.figure(figsize=[10,10])
plt.imshow(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))出力結果

きれいに検出できました!
モデルの比較 (MPI, COCO)
ちなみにモデルをCOCOにするとこんな感じです。
複数人(i=5)
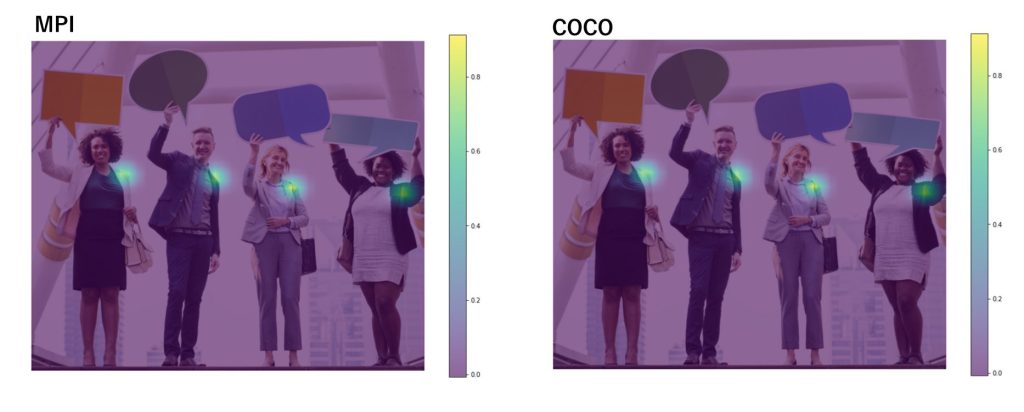
これは同じですね!
複数人(i=24)
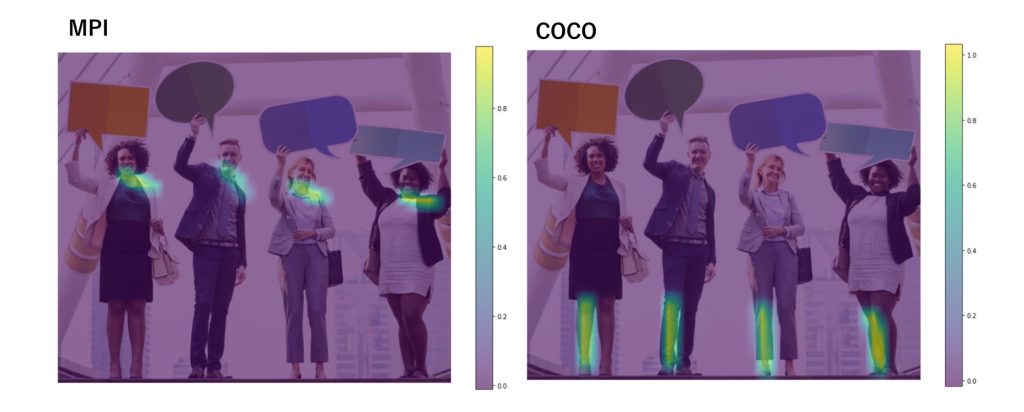
これは見ている部分が大分変わりましたね!COCOはひざ下あたりになりました。
最後に骨格検出結果です。

MPIの方がキレイにでてますね!
きっと得意不得意があるとは思います。
今回の検証は以上になります。


コメント